A View Into Our TimescaleDB Migration
By Goldflag
Ever since Tomato.gg first came online in August 2020, Tomato.gg is likely the only WoT stats tracker with indefinite data retention.
From what I can tell:
- wotlabs.net appears to wipe recent stats after ~6 months
- wot-life.com only keeps recent stats for 30 days
- wotcharts.eu says its database is only 16gb
- wot-numbers.com only shows 21 days of recent stats
Keeping battle data forever has a cost, as ever-increasing table sizes put increased load onto existing hardware. I've had to migrate the Tomato.gg database to better hardware three times in the last three years, with the most recent one being completed last week.
My Postgres database measured at 600+ GB at the time of the migration, and the largest table had almost 2 billion rows.
postgres=# select count(*) from eu.sessions;
count
------------
1971382979
(1 row)
The largest table stored session data for the EU server
Why I needed to migrate
Tomato.gg runs thousands of scheduled queries each day to update
- Tank stats (for every single tank on EU/NA/Asia)
- Map stats
- Recent player rankings
- Overall player rankings
These queries happen for every single tank on EU, NA and Asia servers, and are extremely resource intensive.
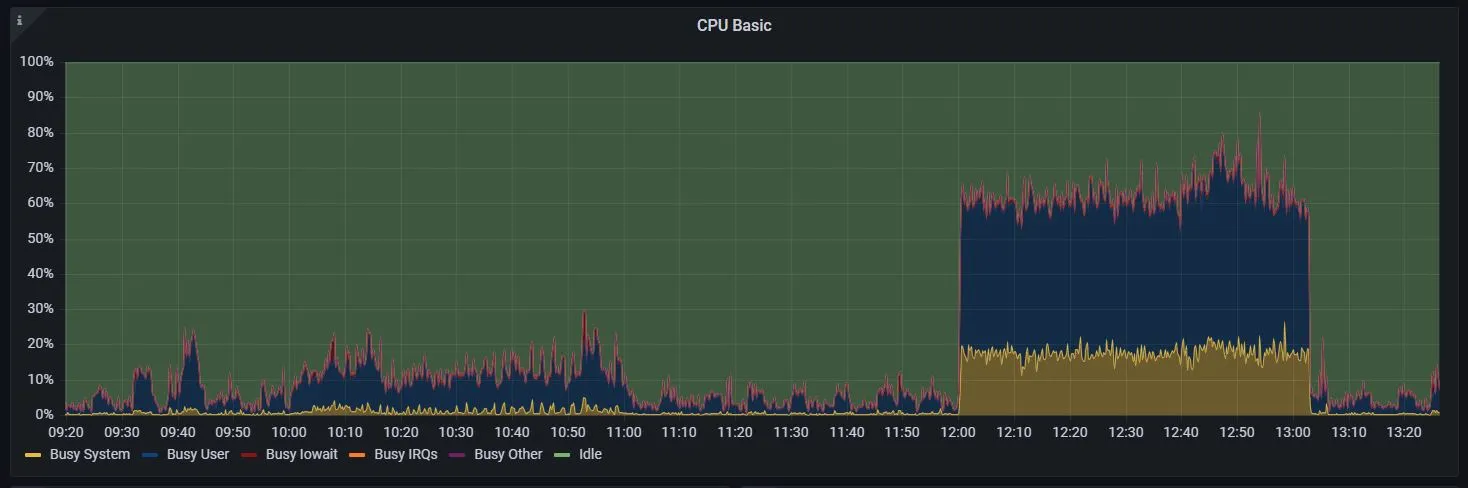 Once CPU usage reached over around 40%, the site became unusable for many users
Once CPU usage reached over around 40%, the site became unusable for many users
Our PostgreSQL database ran on a AX101 dedicated server rented from Hetzner since . The machine had a Ryzen 9 5950x and 128 GB of memory, but still struggled to keep up with the automated queries. There were extended periods of extremely slow load times for users when these queries were running, and sometimes the database was unavailable entirely. This made sense because vanilla Postgres is an OLTP (Online transaction processing) database that is poorly suited for timeseries data, which was the vast majority of what I used it for.
At this point I realized I had to find a way to improve database performance. These were the things I needed to do improve performance.
Use a Timeseries database

I settled on using TimescaleDB, a Postgres extension that turns your Postgres database into a timeseries DB by automatically parittioning data by time. I was super excited when I first read the TimescaleDB marketing articles since they legitimately made it seem like they're 1000x faster than Postgres for timeseries workloads. The discovered the real performance was norwhere near as good as advertised.
TimescaleDB also has other neat features like native compression, but due to the nature of WoT battle data being pretty random I achieved very poor compression ratios.
TimescaleDB is nowhere as fast as actual timeseries databases like Clickhouse or VictoriaMetrics, but it would be enough for my use case and would require minimal extra work as the main benefit of TimescaleDB for me is it being a PostgreSQL extension.
Tune my PostgreSQL instance (I had been running on the default configuration the whole time)
Upgrade the hardware
I rented a Hetzner's new AX102 server which has the newer Ryzen 9 7950X3D processor. I looked up some benchmarks, and it appears to be ~25% faster than the 5950x. Compared to 2x 3.84 TB on the AX101, Hetzner reduced the disk space on the AX102 servers to only have 2x 1.92 TB drives, which is pretty unforunate since I will have to be much more careful about my disk space usage.
The Migration
I used the build-in PostgreSQL backup and restore methods (pg_dump and pg_restore) for the migration. I didn't require anything fancier since the database was only around 400 GB excluding indexes. This post helped me figure out the optimal parameters to save the most time. This process took around 3-4 hours before the new database was ready to go. I manually pg_dumped new data from this 3-4 hour period and backfilled it to the new database, meaning minimal battle data was lost.
Migrating the database to an entirely new server allowed me to upgrade from Postgres 13.9 to 15.5 safely and with very little downtime. I was not knowledgeable enough to safely upgrade an existing Postgres instance to a newer version.
I did multiple test runs of the migration to make sure everything was working properly.
Data Compression
TimescaleDB advertised data compression ratios of 10+, which I was very excited about because running out of disk space has been a big problem in the past. Before I knew about Hetzner's cheap dedicated servers. I spent hundreds of dollars a month of overpriced and underpowered DigitalOcean VPS. In 2022, I spent $300 a month to host the Tomato.gg database in 4 vCPU VPS with only 600GB of disk space.
Anyway, I tried TimescaleDB native compression in some of my tables in one of my migration test runs and got pitiful compression ratios.
hypertable_name | pg_size_pretty
--------------------------+----------------
player_battles_advanced1 | 616 MB
player_battles_advanced2 | 11 GB
player_battles_advanced3 | 571 MB
player_battles_advanced4 | 448 MB
player_battles_advanced5 | 456 MB
player_battles_advanced1 is the uncompressed table. All tables below it are clones compressed with different parameters.
The size of my table on disk only decreased by around 25% at most! And when I compressed with non-optimal parameters, the table became 20x bigger after compression as seen with player_battles_advanced2. To be fair to the compression, a substantial portion of the table's footprint are the existing indexes so the actual compression ratio is better than it appears.
Looking at TimescaleDB's compression methods, it does make sense why my tables didn't compress well.
The compression methods that TimescaleDB uses for integers include delta encoding, simple-8b, and run-length encoding. All of these work really well for things like sensor data, where values change very little from one moment to the next. However, WoT player battle performance data is essentially random from one battle to the next. There no correlation in stats from battles 10 minutes apart or 10 days apart.
Timescale uses XOR-based compression for compressing floating point numbers, but there are almost all columns in my database are integer. It's unclear to me whether Timescale can use XOR-based compression for integers, but even if it did I think it would suffer from the same problems as the other compression algorithms.
None of the tables in the current production database are utilizing TimescaleDB compression, but I may revisit this in the future.
There are actually a couple of tables in the database that I think would compress well, but they're pretty small.
Results
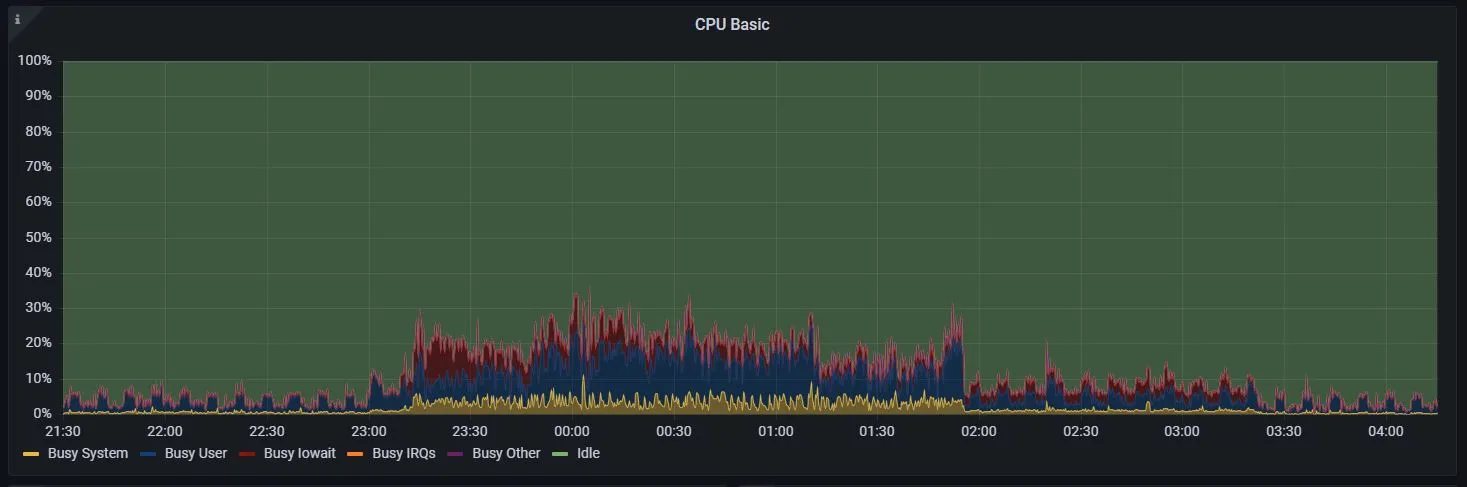 Old CPU usage (Vanilla Postgres)
Old CPU usage (Vanilla Postgres)
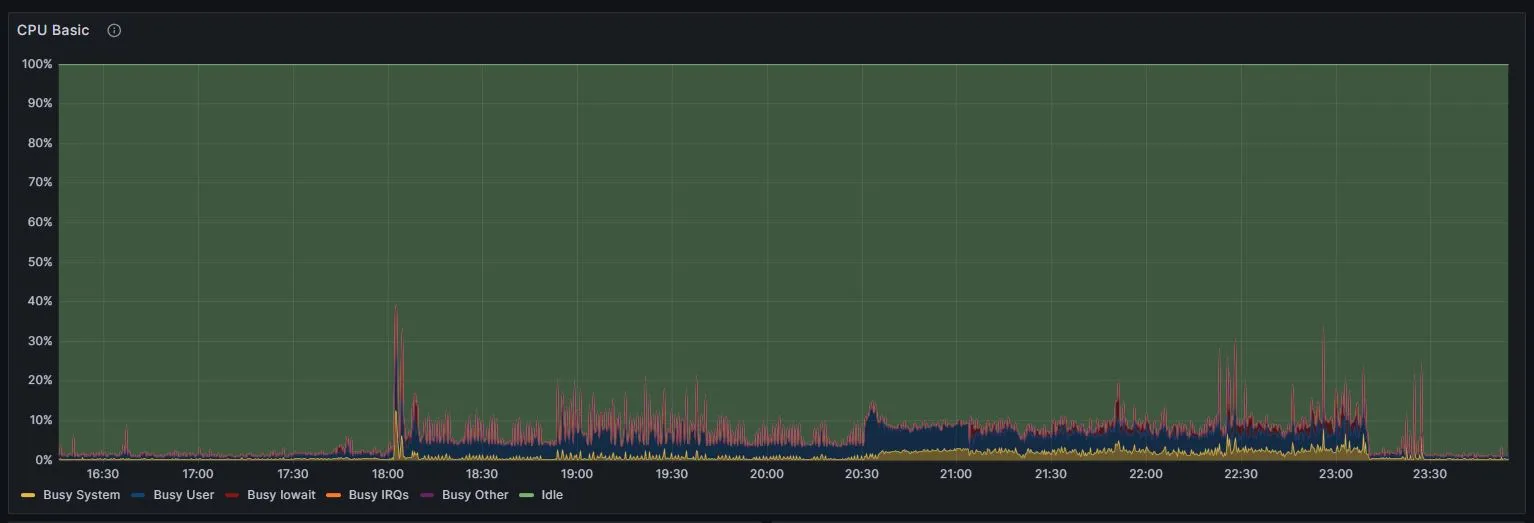 New CPU usage (TimescaleDB)
New CPU usage (TimescaleDB)
This isn't a perfect comparison due to some changes I may have made to the cron jobs setup, but both charts show approximately the same query workload for the old and new databases.
TimescaleDB Benchmarks
Here are some benchmarks I performed comparing my old to new database. This isn't really a fair comparison of TimescaleDB vs vanilla Postgres, and is more of an assesment of Tomato.gg's current vs old setup.
Important caveats:
- Old database has a weaker CPU (5950X vs 7950X3D)
- Old database is running an older Postgres version. Vanilla Postgres 15.5 has non-trivial performance improvements compared to 13.9.
- I did these benchmarks after the migration was completed, so the old database is missing the last 4-5 days of data. This should give the old DB a small advantage.
- The new database was tuned using
timescaledb-tunewereas the old database used the default Postgres configuration.
Feel free to make fun of how my queries. I haven't learned how to write optimal SQL yet.
Benchmark 1
SELECT
player_battles_advanced.tank_id,
COUNT(*) AS battles,
ROUND(AVG(player_battles_advanced.damage)) AS avg_damage
FROM
player_battles_advanced
JOIN tanknames ON player_battles_advanced.tank_id = tankNames.id
WHERE
arena_gui = 1
AND player_battles_advanced.battle_time > now() - interval '60 day'
GROUP BY
player_battles_advanced.tank_id
player_battles_advanced is a table with 47 columns and around 23 million rows.
Results are the average of 3 runs.
| Results | 240 day interval | 120 day interval | 60 day interval | 14 day interval |
|---|---|---|---|---|
| Postgres 13.9 | 2.889 s | 2.508 s | 2.297 s | 2.118 s |
| TimescaleDB (Postgres 15.5) | 2.647 s | 1.573 s | 0.667 s | 0.427 s |
Converting player_battles_advanced to a TimescaleDB hypertable reduced query times by up to 80%. In production, I generally use a 30 or 60-day interval for queries like these.
Notice that TimescaleDB performance gets better as the interval decreases. This is thanks to TimescaleDB partitioning the table by timestamp. For the 240-day interval query we are scanning almost the entire table so the partitions aren't very useful.
Benchmark 2
SELECT
maps.display_name,
COUNT(*) AS battles,
CASE
WHEN battle_type = 0 THEN 'standard'
WHEN battle_type = 1 THEN 'encounter'
WHEN battle_type = 2 THEN 'assault'
END as battle_type,
ROUND(
COUNT(
CASE
WHEN finish_reason = 3 THEN 1
END
) * 100 / COUNT(*) :: decimal,
2
) AS time_expired_rate,
ROUND(
COUNT(
CASE
WHEN WON THEN 1
END
) * 100 / COUNT(*) :: decimal,
2
) AS winrate,
spawn,
ROUND(AVG(damage)) AS avg_damage,
ROUND(AVG(frags), 2) AS avg_frags,
ROUND(AVG(spotting_assist)) AS avg_spotting,
ROUND(AVG(tracking_assist)) AS avg_tracking,
ROUND(AVG(sniper_damage)) AS avg_sniper_damage,
ROUND(AVG(shots_fired), 2) AS avg_shots,
ROUND(AVG(direct_hits), 2) AS avg_hits,
ROUND(AVG(penetrations), 2) AS avg_pens,
ROUND(AVG(spots), 2) AS avg_spots,
ROUND(AVG(damage_blocked)) AS avg_blocked,
ROUND(AVG(potential_damage_received)) AS avg_potential_damage_recieved,
ROUND(AVG(base_capture_points), 2) AS avg_cap,
ROUND(AVG(base_defense_points), 2) AS avg_def,
ROUND(AVG(life_time)) AS avg_life_time,
ROUND(AVG(duration)) AS duration,
ROUND(AVG(distance_traveled)) AS avg_distance_traveled
FROM
player_battles_common
JOIN maps on player_battles_common.map_id = maps.geometry_id
JOIN tanknames on player_battles_common.tank_id = tanknames.id
WHERE
battle_time > now() - interval '30 day'
AND arena_gui = 1
GROUP BY
map_id,
maps.display_name,
battle_type,
spawn
player_battles_common is a table with 41 columns and around 550 million rows.
| Results | 60 day interval | 30 day interval |
|---|---|---|
| Postgres 13.9 | 218.803 s | 101.226 s |
| TimescaleDB (Postgres 15.5) | 21.919 s | 13.589 s |
This benchmark is nearly identical to a query that is actually used in production to calculate map stats. We observe a near 10x increase in query performance.
Benchmark 3
WITH QUERY AS (
SELECT
player_id,
tank_id,
1 AS battles,
CASE
WHEN WON THEN 1
ELSE 0
END AS wins,
shots_fired,
direct_hits,
penetrations,
damage,
sniper_damage,
frags,
spotting_assist,
tracking_assist,
spots,
damage_blocked,
damage_received,
potential_damage_received,
damage_received_from_invisible,
base_capture_points,
base_defense_points,
CASE
WHEN life_time >= (duration - 1) THEN 1
ELSE 0
END AS survived,
life_time,
distance_traveled
FROM
player_battles_common
WHERE
arena_gui = 1
AND battle_time > now() - interval '30 day'
AND player_id BETWEEN 1000000000
AND 2000000000
)
SELECT
tank_id,
short_name AS name,
nation,
tier,
type AS class,
is_premium AS isPrem,
images.contour_icon as image,
SUM(battles) AS battles,
ROUND(
SUM(wins) * 100 / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS winrate,
ROUND(SUM(damage) / NULLIF(SUM(battles), 0)) AS damage,
ROUND(SUM(sniper_damage) / NULLIF(SUM(battles), 0)) AS sniper_damage,
ROUND(
SUM(frags) / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS frags,
ROUND(SUM(spotting_assist) / NULLIF(SUM(battles), 0)) AS spotting_assist,
ROUND(SUM(tracking_assist) / NULLIF(SUM(battles), 0)) AS tracking_assist,
ROUND(
SUM(shots_fired) / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS shots_fired,
ROUND(
SUM(direct_hits) / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS direct_hits,
ROUND(
SUM(penetrations) / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS penetrations,
ROUND(
SUM(direct_hits) * 100 / NULLIF(SUM(shots_fired), 0) :: NUMERIC,
2
) AS hit_rate,
ROUND(
SUM(penetrations) * 100 / NULLIF(SUM(direct_hits), 0) :: NUMERIC,
2
) AS pen_rate,
ROUND(
SUM(spots) / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS spots,
ROUND(SUM(damage_blocked) / NULLIF(SUM(battles), 0)) AS damage_blocked,
ROUND(SUM(damage_received) / NULLIF(SUM(battles), 0)) AS damage_received,
ROUND(
SUM(damage_received_from_invisible) / NULLIF(SUM(battles), 0)
) AS damage_received_from_invisible,
ROUND(
SUM(potential_damage_received) / NULLIF(SUM(battles), 0)
) AS potential_damage_received,
ROUND(SUM(spotting_assist) / NULLIF(SUM(battles), 0)) AS spotting_assist,
ROUND(
SUM(base_capture_points) / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS base_capture_points,
ROUND(
SUM(base_defense_points) / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS base_defense_points,
ROUND(SUM(life_time) / NULLIF(SUM(battles), 0)) AS life_time,
ROUND(
SUM(survived) * 100 / NULLIF(SUM(battles), 0) :: NUMERIC,
2
) AS survival,
ROUND(SUM(distance_traveled) / NULLIF(SUM(battles), 0)) AS distance_traveled
FROM
query
JOIN tanknames ON tanknames.id = tank_id
JOIN images ON images.id = tank_id
GROUP BY
tank_id,
short_name,
tier,
nation,
type,
is_premium,
contour_icon
ORDER BY
battles DESC;
| Results | 120 day interval | 60 day interval | 30 day interval | 14 day interval |
|---|---|---|---|---|
| Postgres 13.9 | 60.498 s | 15.532 s | 11.032 s | 4.76 s |
| TimescaleDB (Postgres 15.5) | 28.678 s | 18.045 s | 8.013 s | 5.072 s |
This query is also identical to one used in production. Apart from the 120-day interval, TimescaleDB isn't faster here for some reason. I don't really know why this is the case.
Benchmark 4
SELECT
i.username,
s.player_id,
RANK() over (
ORDER BY sum(damage)/sum(battles) DESC
) AS rank,
sum(battles) as battles,
round(sum(wins) :: numeric * 100 / sum(battles), 2) as winrate,
sum(damage) / sum(battles) as dpg,
round(sum(damage) :: numeric / nullif(sum(damager), 0), 2) as dmg_ratio,
round(sum(frags) :: numeric / sum(battles), 2) as frags,
round(
sum(frags) :: numeric / nullif((sum(battles) - sum(survived)), 0),
2
) as kd,
round(sum(survived) :: numeric * 100 / sum(battles), 2) as survived,
round(sum(spots) :: numeric / sum(battles), 2) as spots
FROM
com.sessions s
INNER JOIN com.ids i on s.player_id = i.player_id
WHERE
tank_id = 14609
AND timestamp > 28283160
GROUP BY
s.player_id,
i.username
HAVING
sum(battles) > 24 LIMIT 500;
com.sessions is a table with 13 columns and around 350 million rows.
Results are the average of 3 runs.
| Results | Time |
|---|---|
| Postgres 13.9 | 1.875 s |
| TimescaleDB (Postgres 15.5) | 1.093 s |
The table used in this benchmark was never converted into a TimescaleDB hypertable, so this we aren't seeing as many of the benefits of TimescaleDB here.
Benchmark 5
SELECT
count(*)
FROM
eu.sessions s
INNER JOIN eu.ids i on s.player_id = i.player_id
where
tank_id = 60225
AND timestamp > 28283160
HAVING
sum(battles) > 24;
eu.sessions is a table with 13 columns and around 2 billion rows.
Results are the average of 3 runs.
| Results | Time |
|---|---|
| Postgres 13.9 | 4.832 s |
| TimescaleDB (Postgres 15.5) | 2.175 s |
We still see a big performance jump despite eu.sessions also not being converted to a hypertable.
Final Thoughts
TimescaleDB turned out to not be quite as a good for Tomato.gg as it was for others, but I'm still happy with the performance improvements I achieved with this migration. Now I am able to work on adding more features without worrying about degraded service for users.